OPCODE vs RAPID
Here are some screenshots to summarize the strenghs and weaknesses of both RAPID 2.01 and OPCODE 1.0.
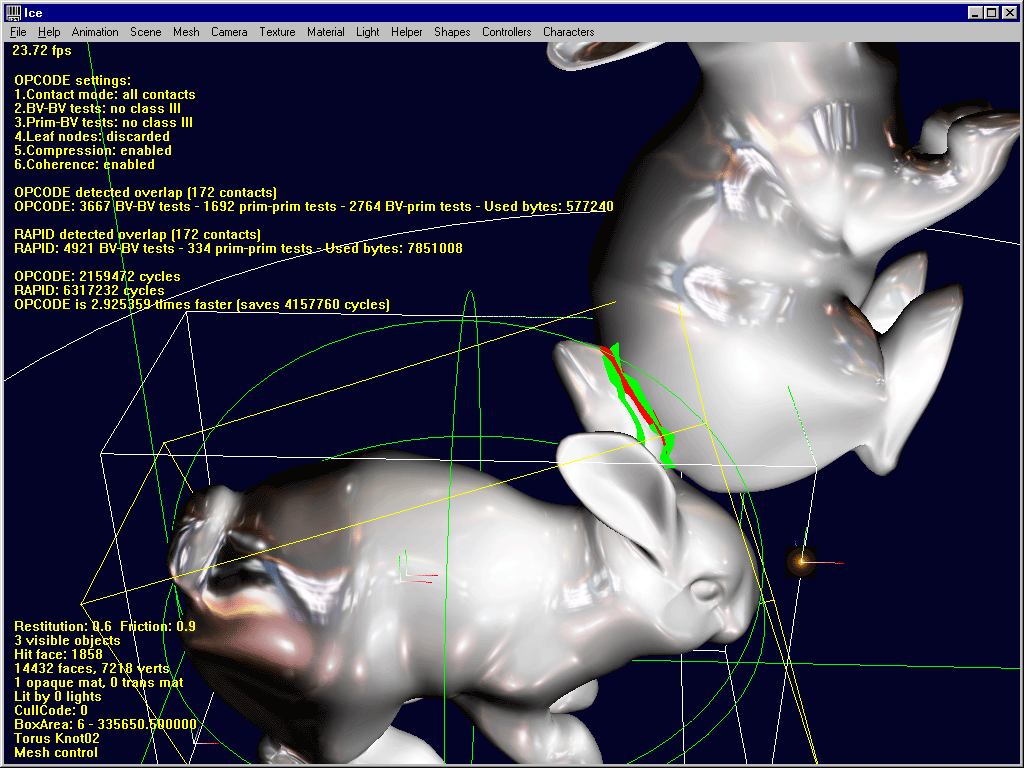
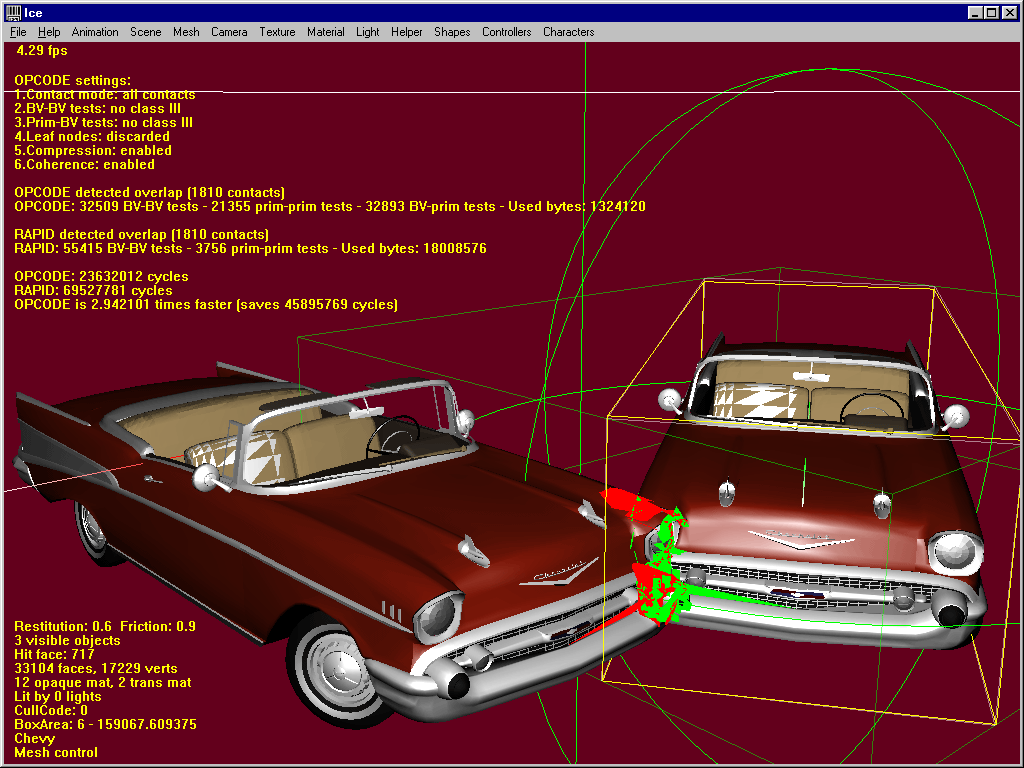
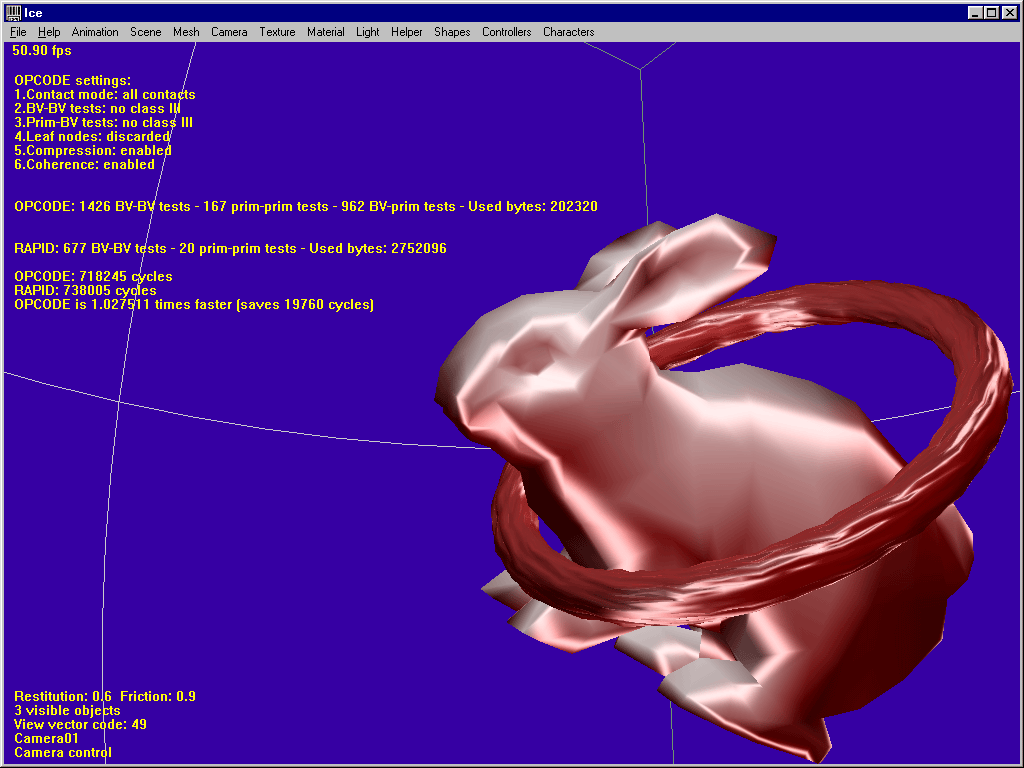
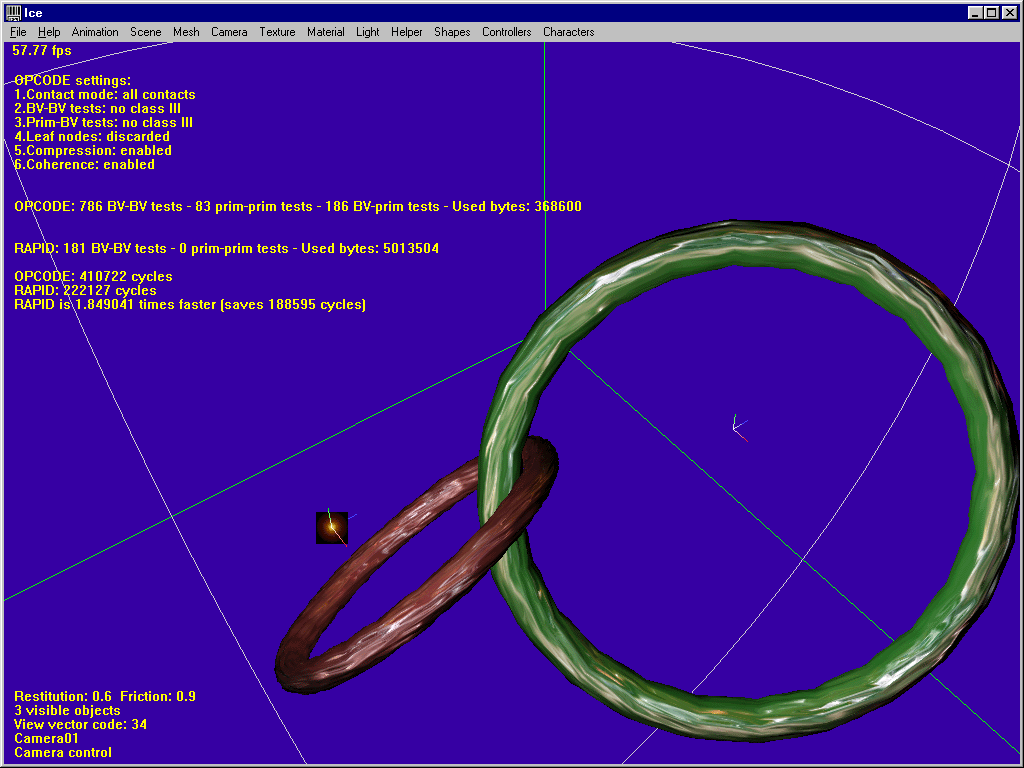
1. Overlap situations
In this shot, default OPCODE settings are used : SAT-lite tests, no leaf nodes, quantized trees. Please note the number of bytes used by the two libs (this is the total for the two models). OPCODE is about 3 times faster, saving about 4 million cycles.
Same settings, other meshes, same conclusion : OPCODE is 3 times faster and runs 17 million cycles faster.
Again, OPCODE is 2.5 times faster and saves 1.3 million cycles.
OPCODE is 3 times faster and saves more than 45 million cycles (lots of faces in there !)
Conclusion :
That one is easy. Basically, RAPID can’t beat OPCODE as soon as there is overlap. I don’t think I’ve seen RAPID run faster even once in those cases…
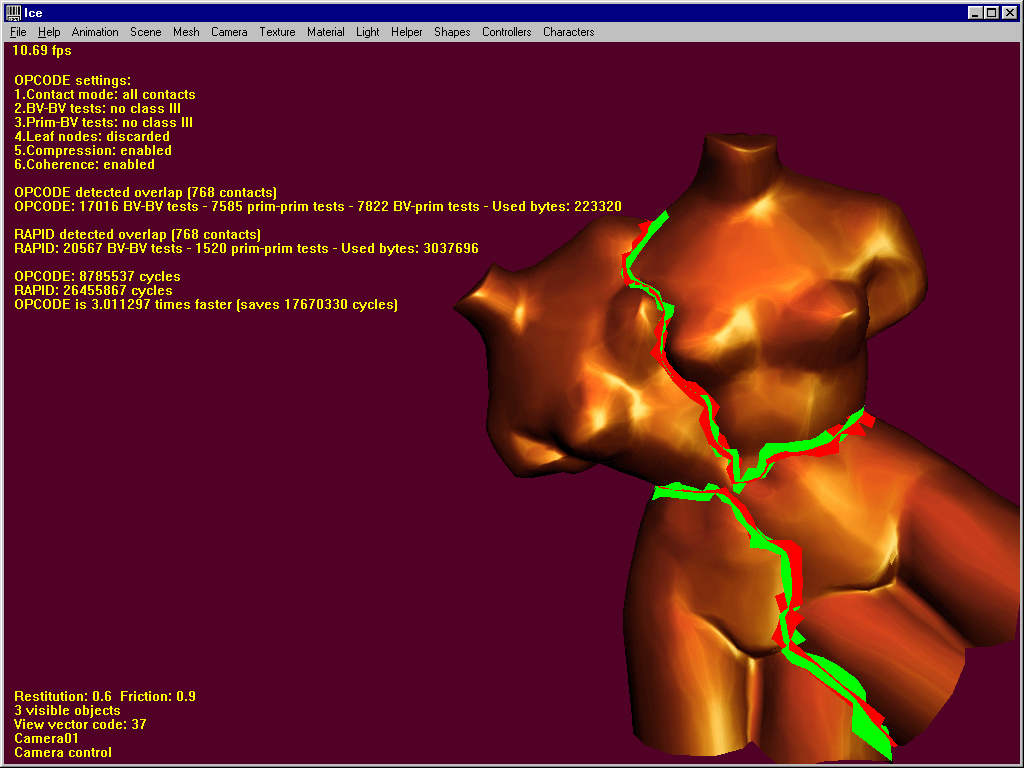
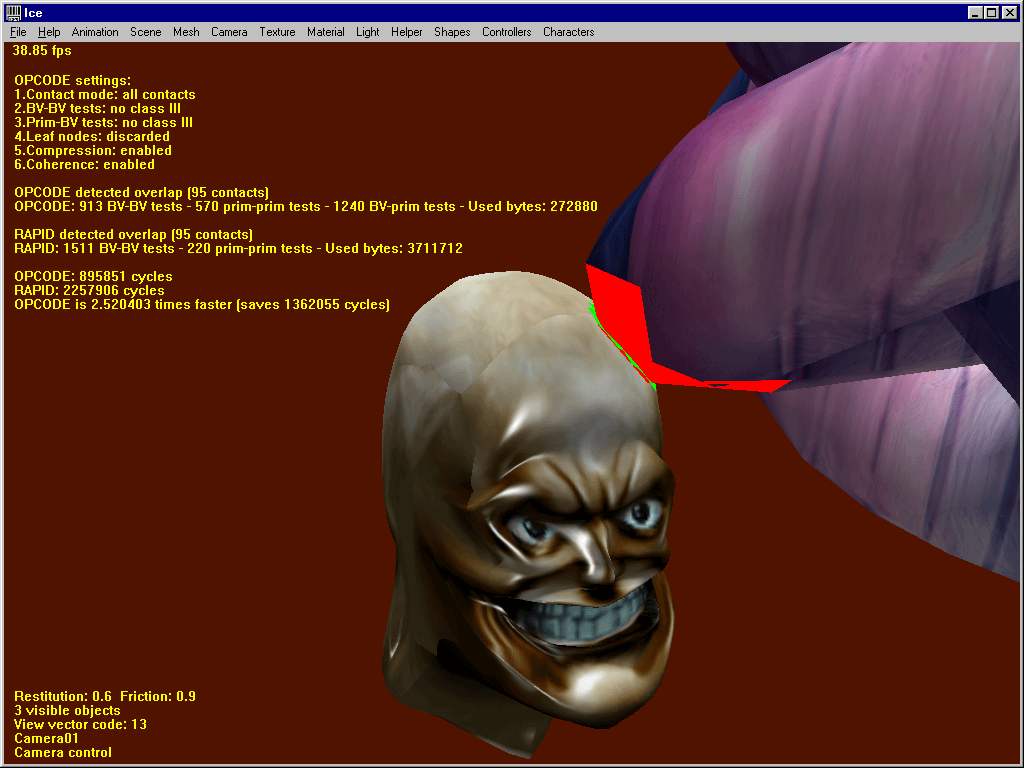
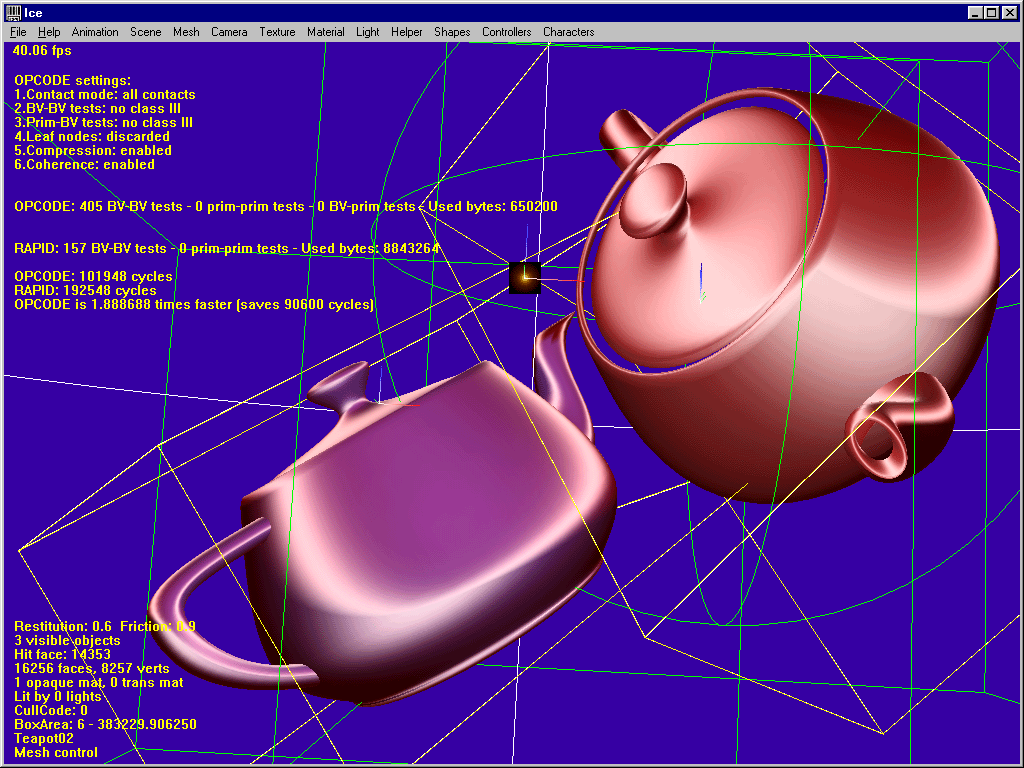
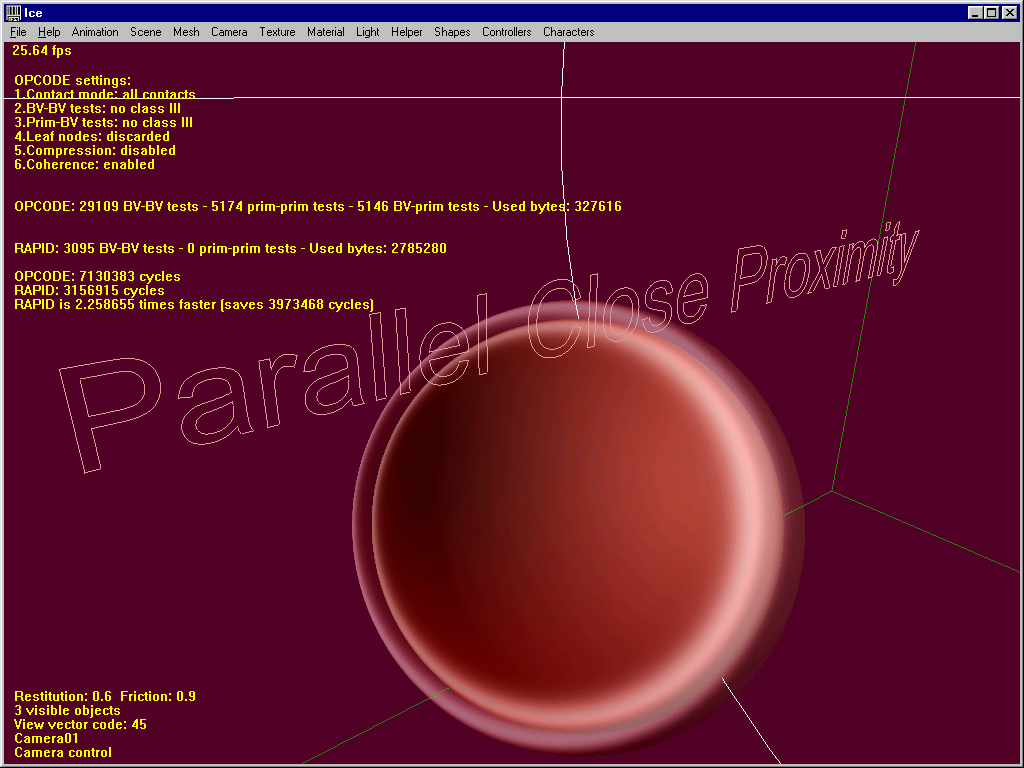
2. Close-proximity situations
Both libs are about as fast. Sometimes OPCODE is slightly faster (as in this shot), sometimes it’s RAPID.
OPCODE works well in this case (about 2 times faster here), but sometimes RAPID runs faster.
OPCODE works well in this particular case, and runs faster in almost all frames of the animation. This is probably due to the models beeing vertically-aligned to begin with.
Once again OPCODE runs slightly faster, even if a lot of tests are performed (about 3 times more tests than RAPID !)
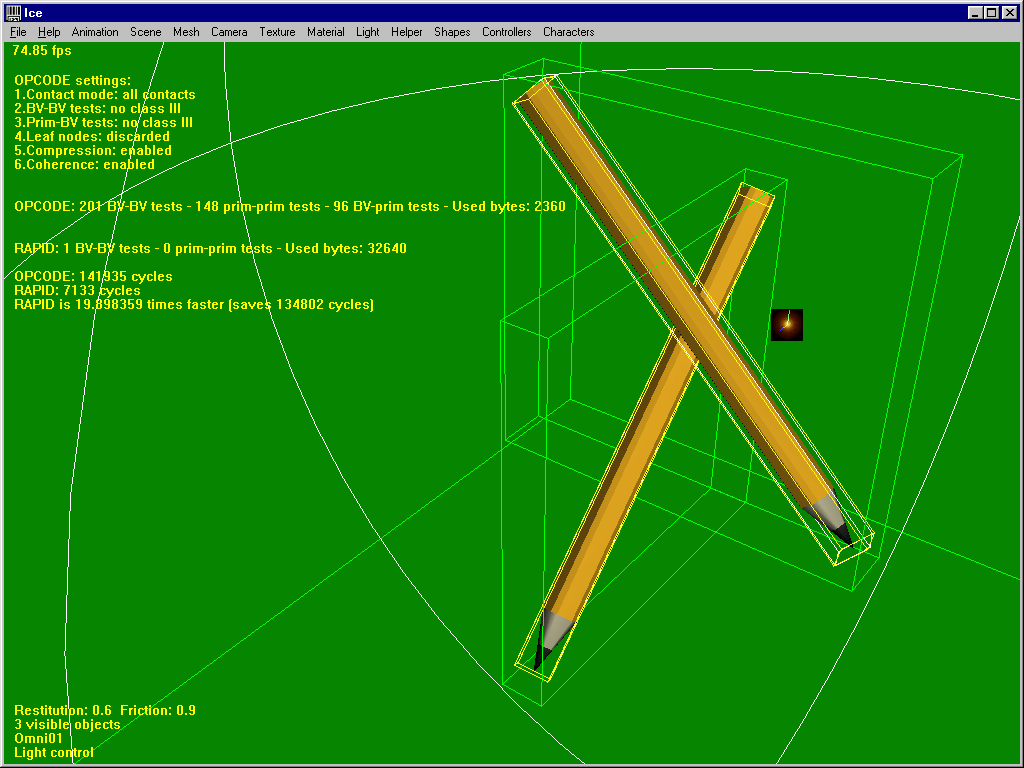
Here’s a typical case where RAPID outperforms OPCODE thanks to the OBBs’ tight fit (whereas you can see the first-level AABBs are particularly bad). Hence RAPID is about 20 times faster here, since a single OBB-OBB test is performed ! Please note it does not save so much cycles anyway.
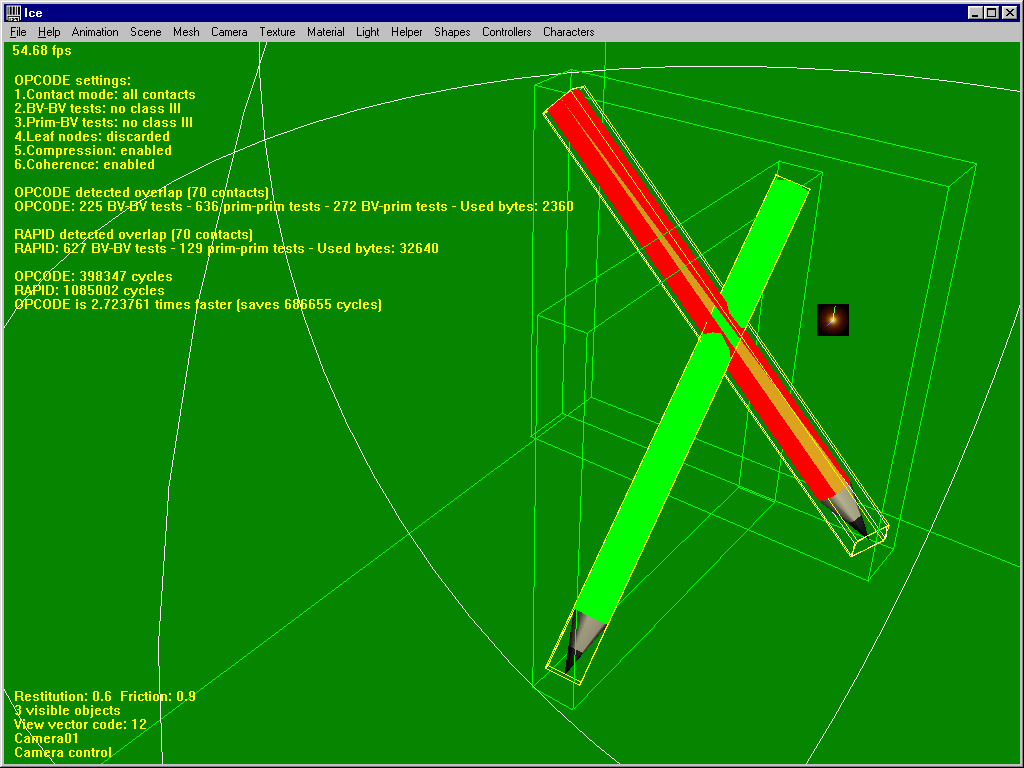
And RAPID is only faster until pencils collide……
===================================================================
News : comments above are obsolete and wrong ! The « first level AABBs » visible in the snapshot are not representative of OPCODE’s first level boxes, since they’re actually built in the model’s OBB space. So I was wrong there, what happens in this scene is the following : since we’re using coarse tests, the first box-box overlap test does not conclude boxes are disjoint ! Hence, more and more tests are performed in vain. (I think the same problem would occur in SOLID)
In order to fix this, you can enable full tests back : suddenly RAPID goes from 20-30 times faster down to 1 (i.e. both libs perform a single test). Of course, using full tests is slower in about all other situations, so this is not a very good move.
Anyway there’s a neat solution : always performing the first BV-BV test completely, regardless of actual settings ! This provides best of both worlds, and actually speeds things up in several other scenes, when a single BV-BV test is enough to prove meshes do not overlap.
This is how things work now in OPCODE. Keep this in mind while reading the conclusion below J
===================================================================
Conclusion :
OPCODE works well in close-proximity cases, except in pathological cases where RAPID is definitely faster. I would say RAPID has a more homogeneous behaviour. (Now, it still needs 10 times more memory J)
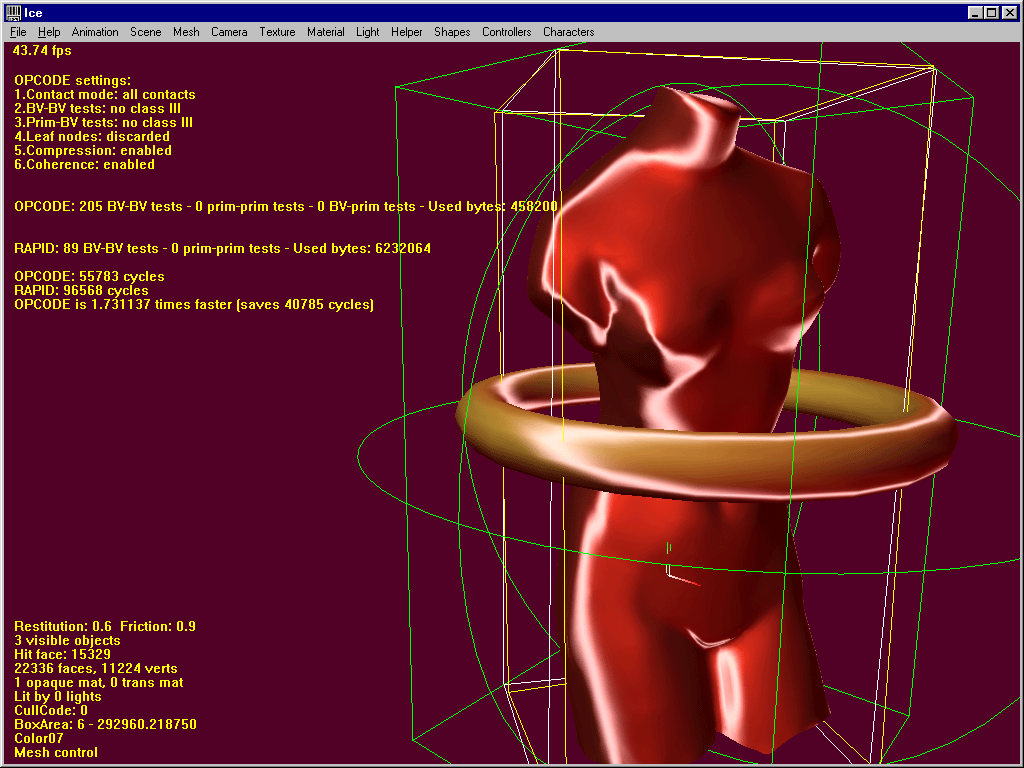
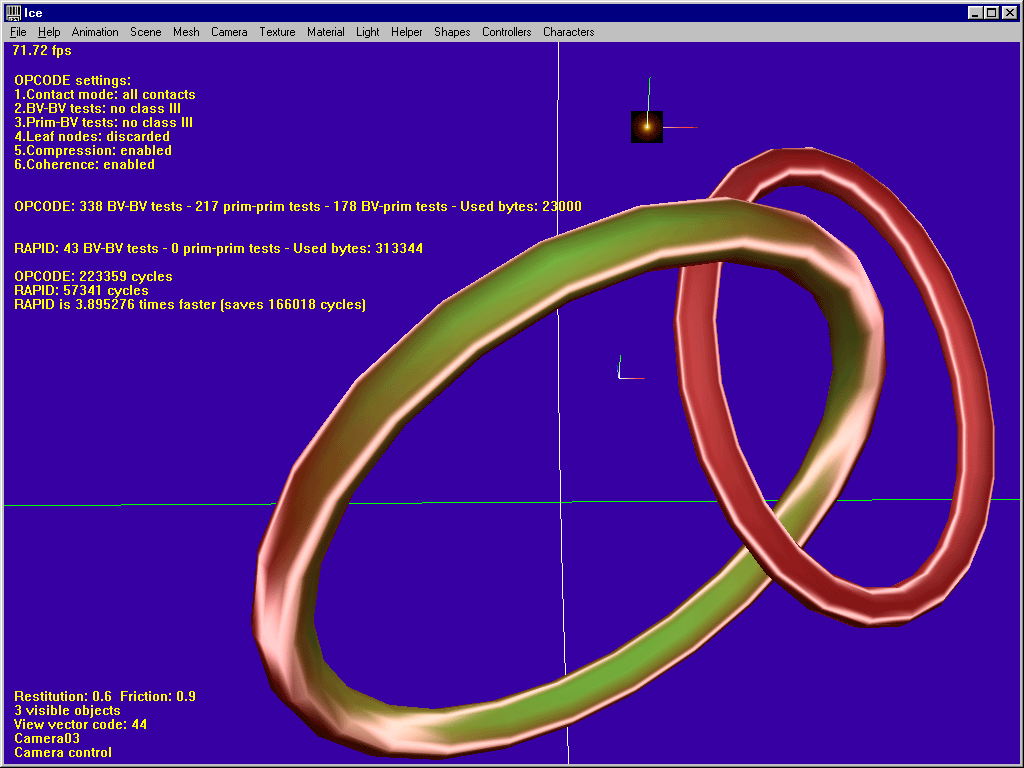
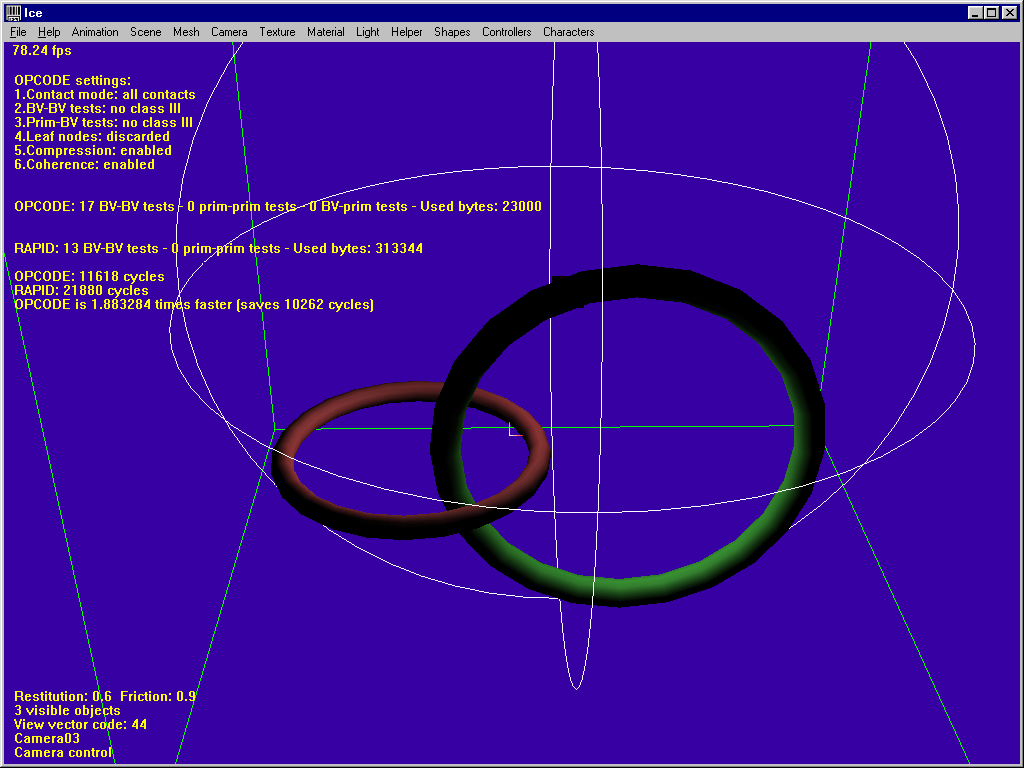
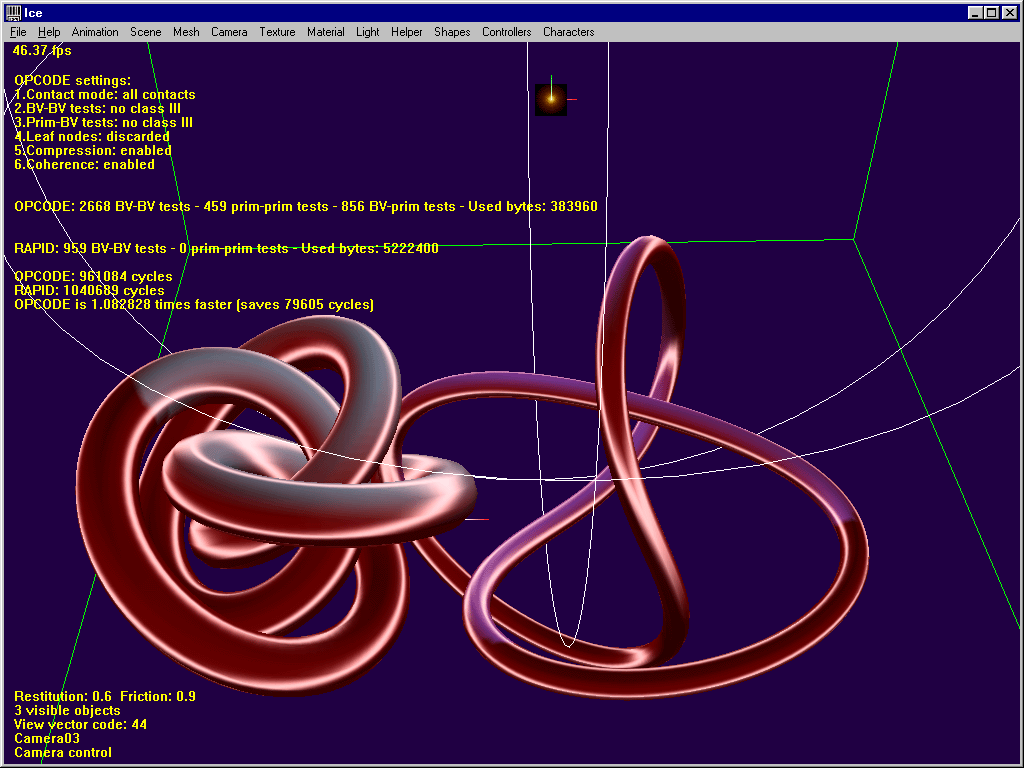
3. Interlocked models
RAPID is about 4 times faster in this shot. Sometimes OPCODE still manages to win the game, but generally speaking OBBs are obviously better in such situations. Anyway note the cute 23000 bytes compared to RAPID’s memory requirements.
RAPID and OPCODE are roughly equivalent in this test.
Conclusion :
RAPID is usually more adapted in those cases, but OPCODE is not that pathetic either…
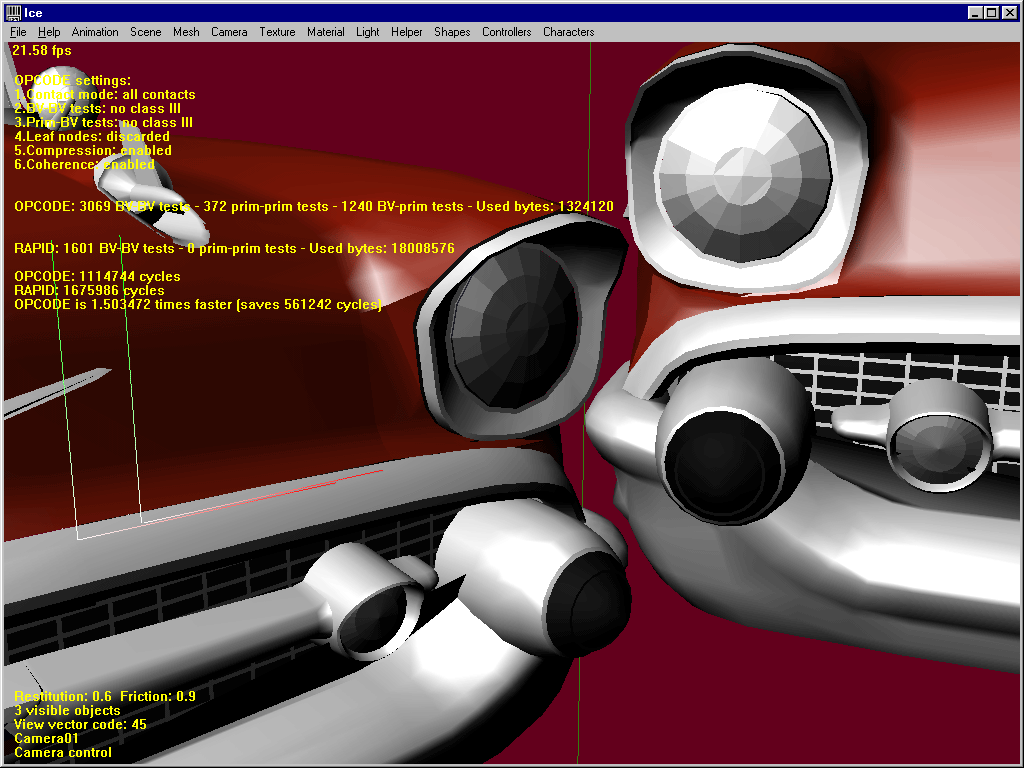
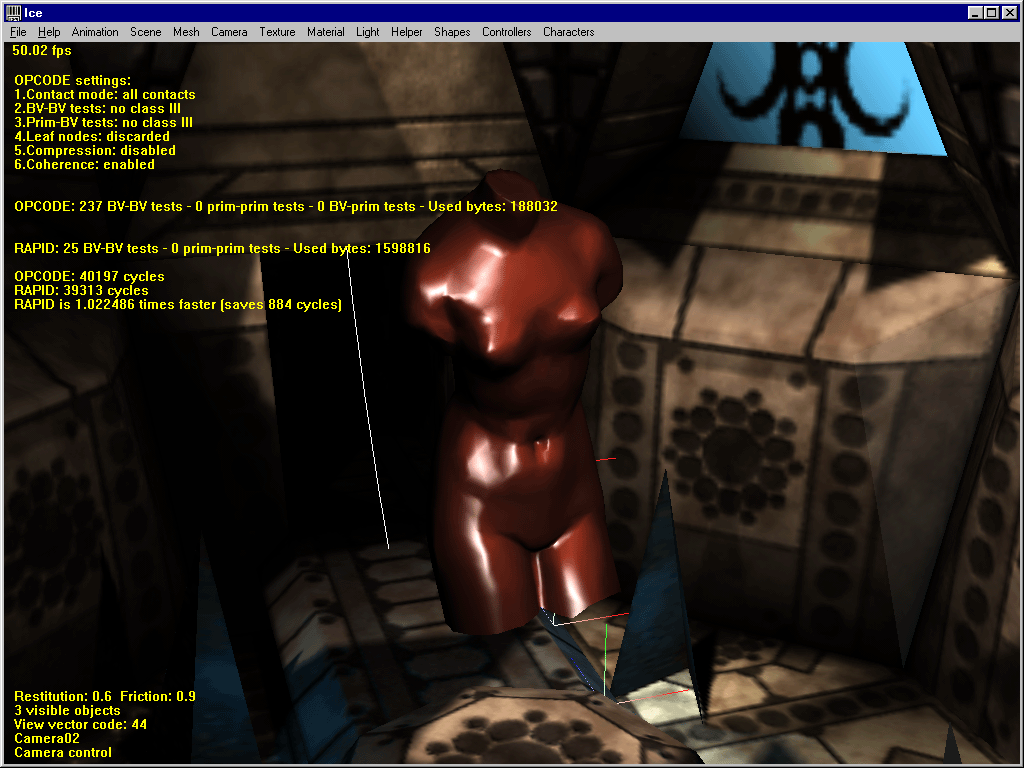
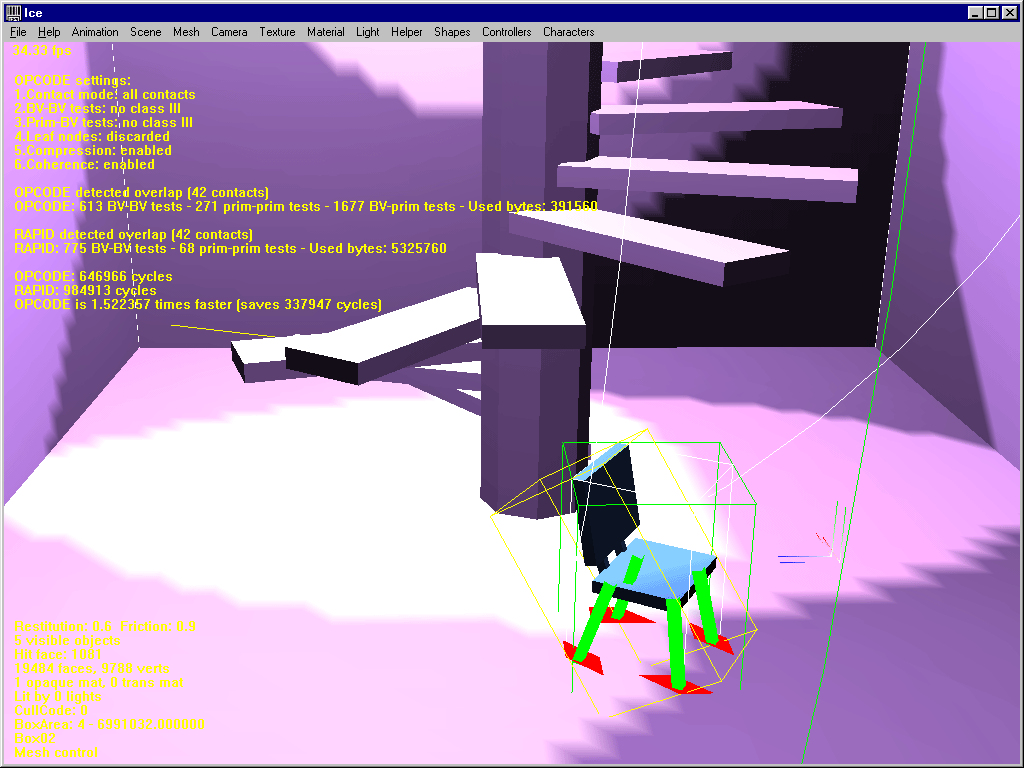
4. Bounded models
This is a bit similar to interlocked models, and RAPID peforms well there. In several cases anyway, both libs are really close to each other. In this shot, the difference is only 884 cycles, i.e. nothing. But it’s interesting to note the same amount of CPU work is dedicated to 25 overlap tests in RAPID, and 237 in OPCODE !
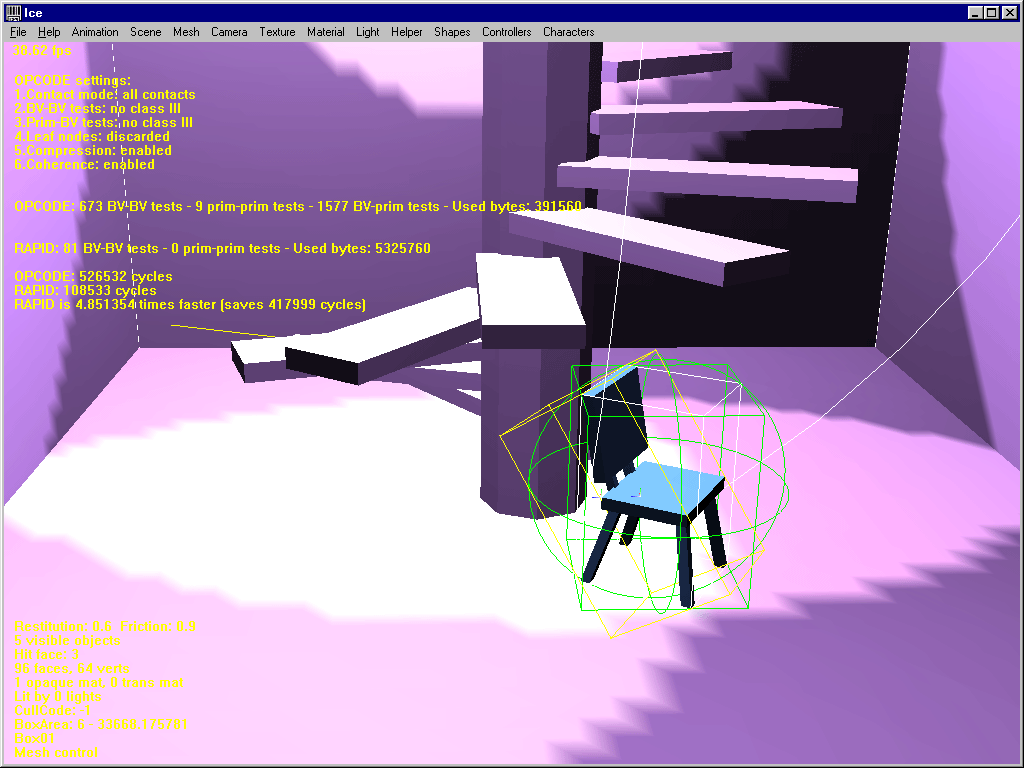
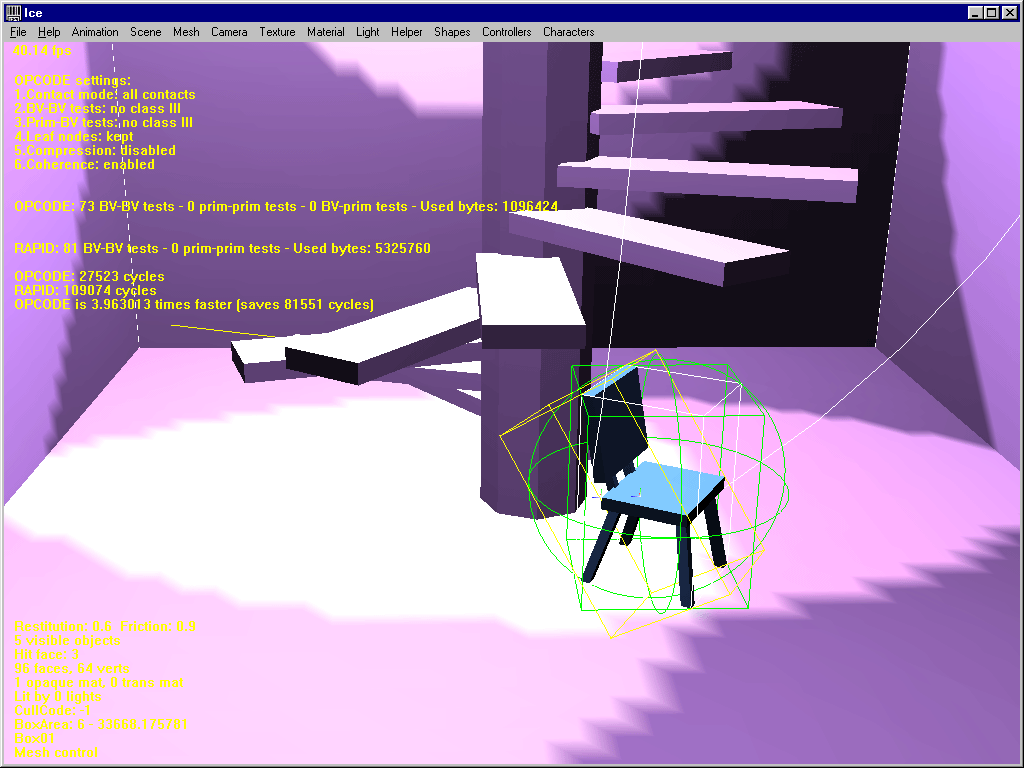
A very interesting scene where a chair model is completely surrounded by a room model. As expected, when the chair collides with the room there’s no competition : OPCODE is faster. Now, if you move the chair a bit upwards, RAPID suddenly fights back and runs almost 5 times faster, saving about 400000 cycles ! Now, change OPCODE’s settings a bit and it becomes 4 times faster again !
Conclusion :
RAPID is probably better here. One strategy then, would be to cut the bounding model in several sub-models.
5. Big Model
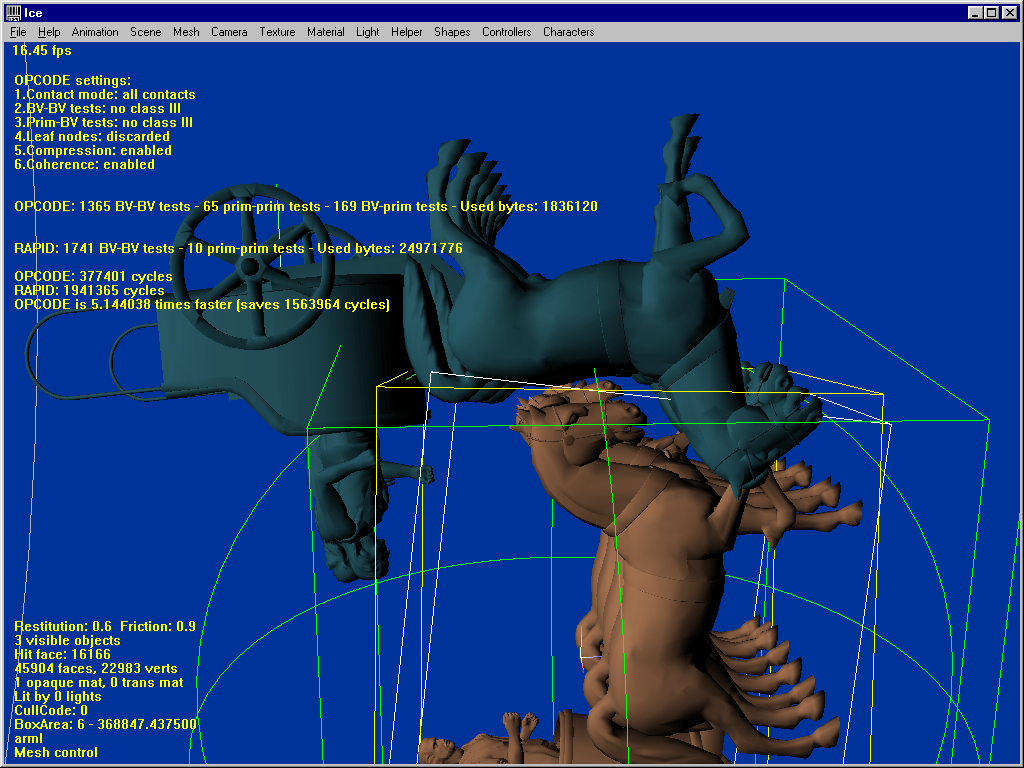
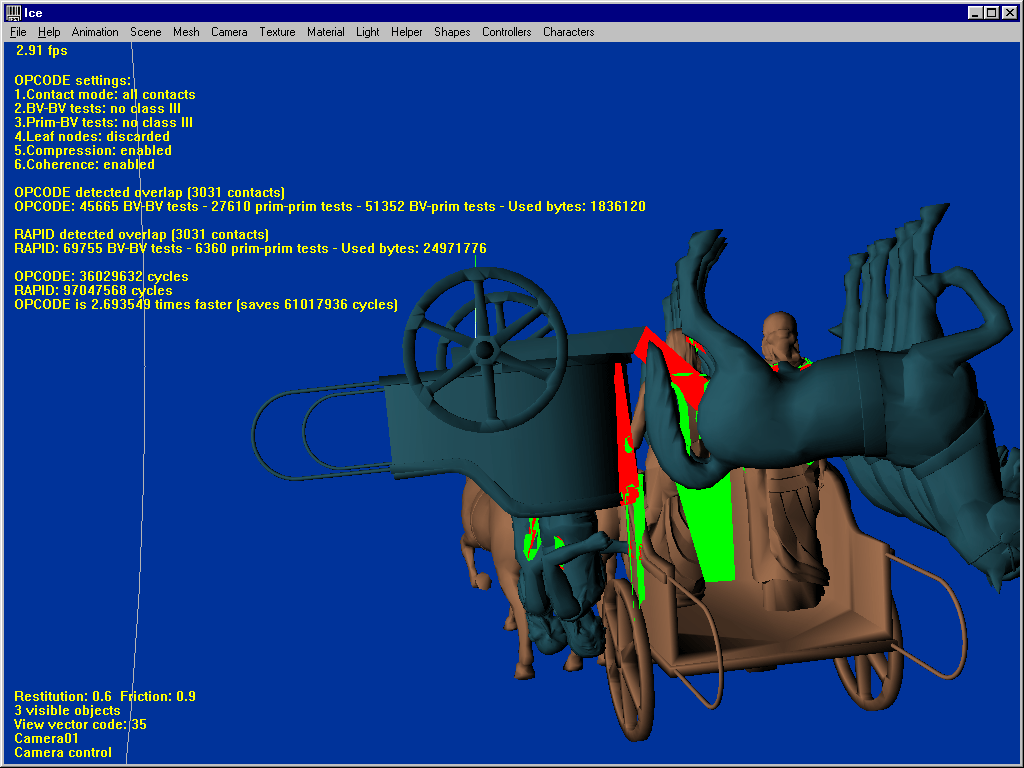
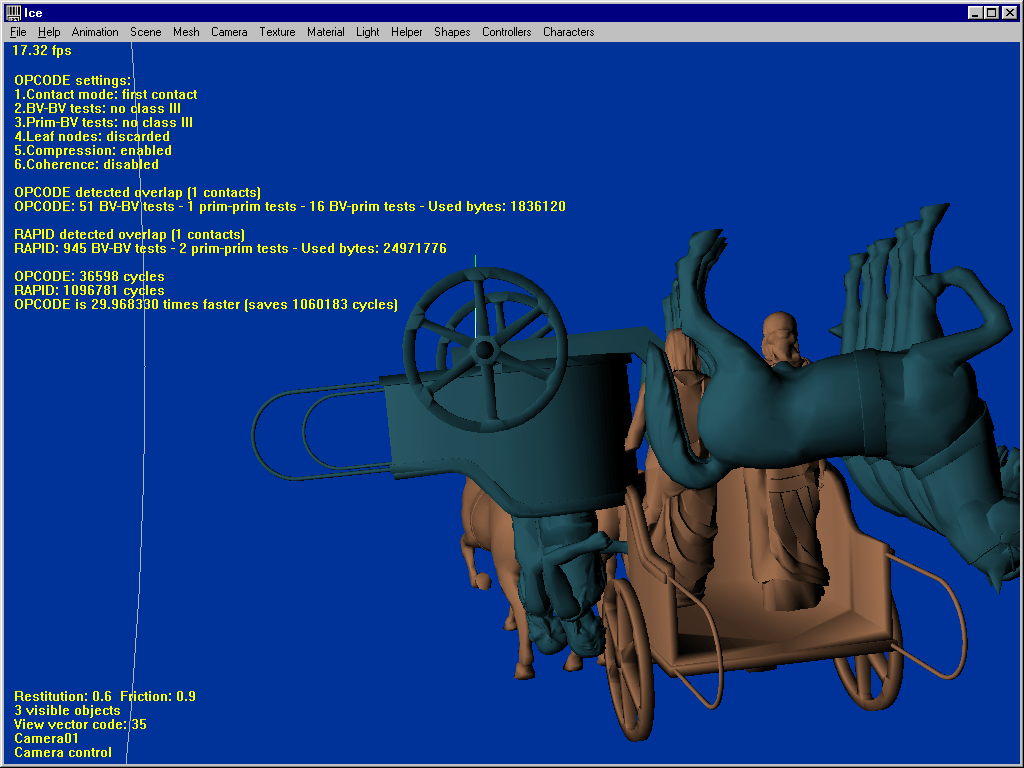
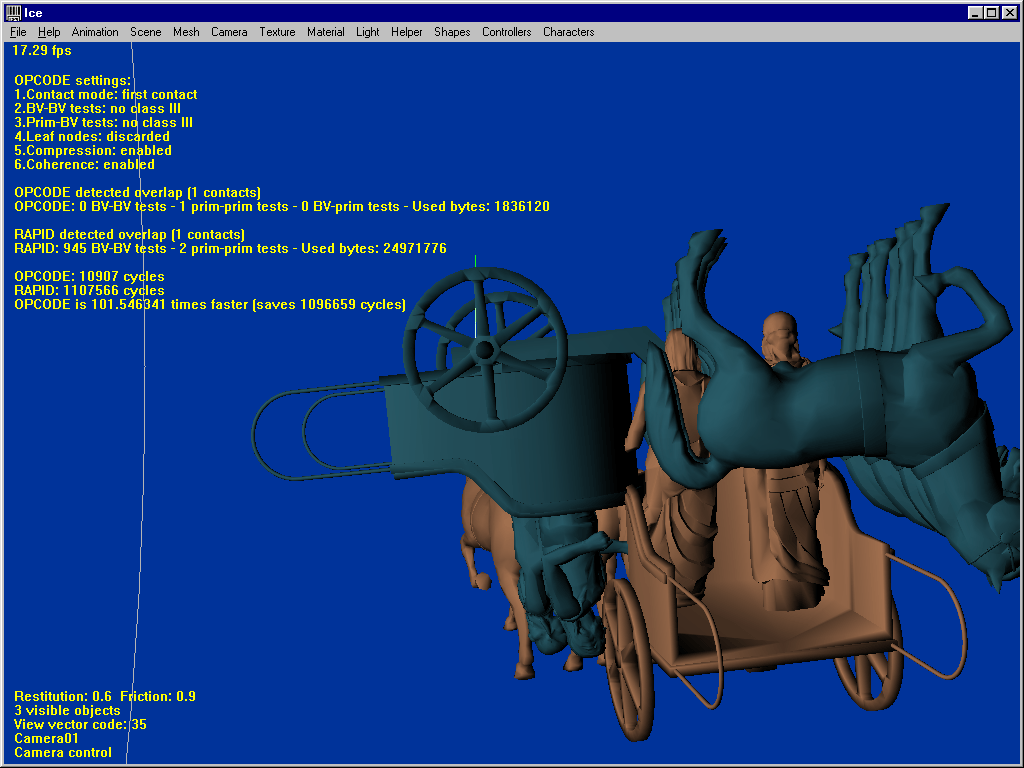
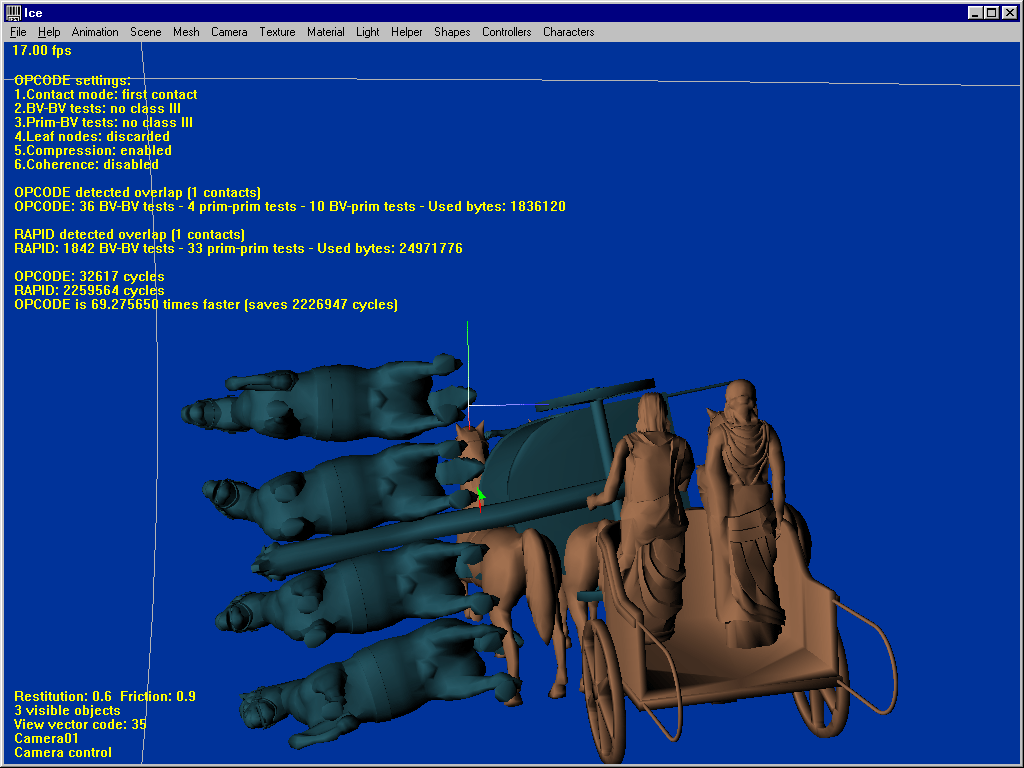
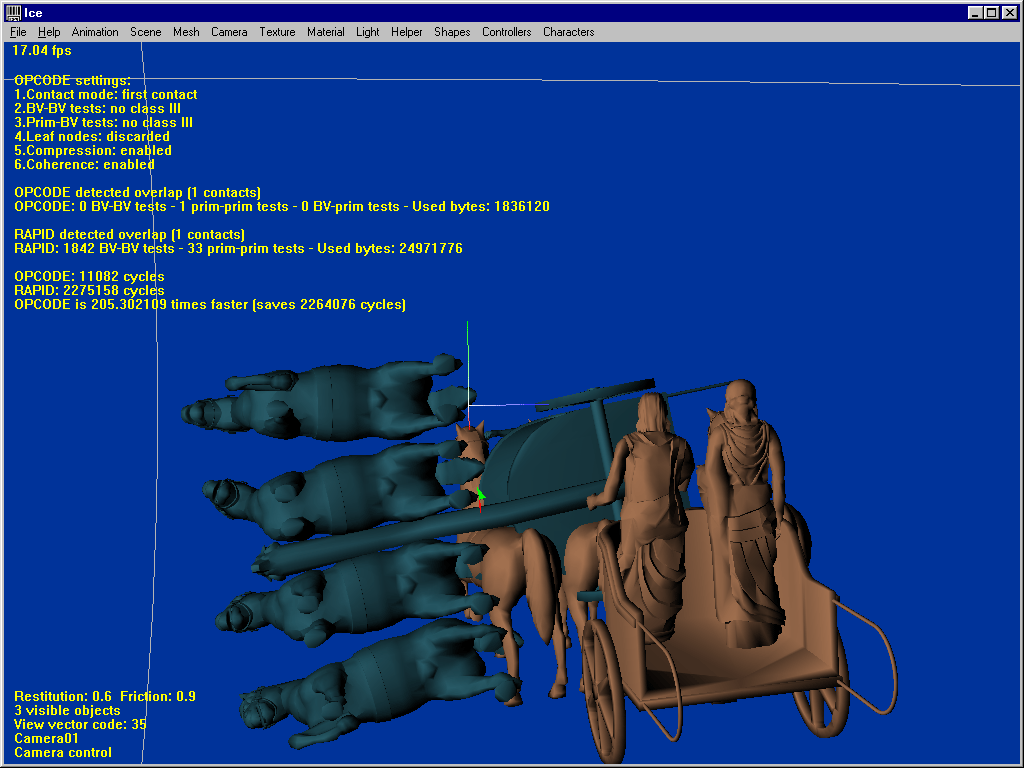
This last test uses two complex models of 45904 faces each, and clearly shows what OPCODE can do. The first shot is a complex close-proximity scenario (not some torus against another torus !) where OPCODE runs 5 times faster than RAPID. Make the models collide, and OPCODE’s strength becomes obvious : 2.6 times faster saving a huge amount of 61 million cycles. Ask for the first contact only, and it becomes 30 times faster than RAPID. Enable temporal coherence and it becomes 101 times faster. Rotate the models a bit, and the same queries respectively run 69 and 205 times faster than RAPID.
Conclusion :
Since on top of that OPCODE needs at least 7.2 times less ram than RAPID, I think the overall conclusion is clear : the lib competes well with state-of-the-art packages, and its new underlying ideas should be tested with OBB trees as well to provide, perhaps, best of both worlds…….
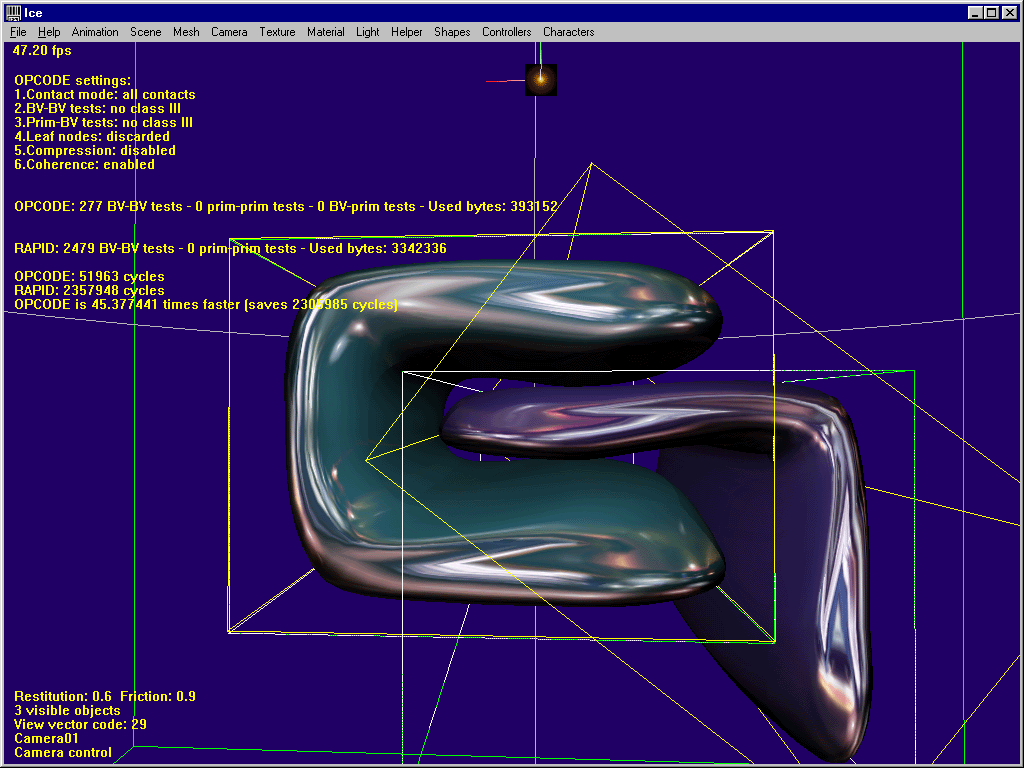
6. Summary : strength & weakness of both libs
Here are two screenshots to summarize the whole thing.
According to Gottschalk, this is definitely the kingdom of OBBs. And indeed, RAPID is a lot faster than OPCODE in this case.
Here’s a typical case where OPCODE is way faster than RAPID, since L-shaped objects are not really in love with OBBs…..
Last modified : April 1, 2001 – Pierre Terdiman
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}