February 24th, 2008
Note: I see a lot of spam already appearing in the comments, so I changed the moderation options. Now a comment will need to be approved before appearing on the blog.
February 24th, 2008
Note: I see a lot of spam already appearing in the comments, so I changed the moderation options. Now a comment will need to be approved before appearing on the blog.
February 23rd, 2008
Uploaded a new Konoko Payne version. Nothing really new here, just bug-fixes, “new” characters (Elite Striker, Ninja…), fixed motion scripts, an automatic camera for the demo-mode, etc. The previously mentioned “blood puddles” are in there, but it’s otherwise basically the same as last time, slightly improved. I just don’t have any time to work on a real “game” with a proper scenario, cutscenes, different levels, nice level design, etc. Or voice acting. Some guy once sent me an email complaining about the MGS2-like dialogs in KP, saying that “it would be better with recorded voices”. Yeah, right. What about this: I hire Amanda Winn-Lee and you pay the bill. Deal?
I’m considering dropping all the commercial libraries used out there (mainly Novodex & Pathengine) to make a proper open source project, but even this takes forever. I don’t know any good open source pathfinding library to replace Pathengine, so I’m kind of stuck here. I could re-implement it myself using John Ratcliff’s AI Wisdom 4 article, but I admit I’m not very motivated for this. It’s always painful to re-do something that already works, it doesn’t feel like making progress. On the other hand, the whole KP project doesn’t evolve very quickly anyway, and an open source version could boost this. Or ruin it completely.
I think I’m reaching a point where I can’t make that project a lot better just by myself. The code is pretty much “done”. Sure the AI could be improved, things could be more polished and more optimized, but the hand-to-hand combat, gun fights, character control, etc, everything’s working well and feels good. Despite this, I have an insanely long “TODO” list for Konoko Payne. Let me check… 93 Kbytes! It’s a vanilla ASCII text file with something like one task per line, and ~2000 lines. So that’s ~2000 things to do. If I do one thing per day, I’d need 2000/365 = 5.47 years to complete the project. This is so depressing. In comparison, I have another “DONE” file listing the things already implemented. I move the tasks from the TODO file to the the DONE file when they’re done. Today the DONE file is 62 KBytes and a little bit more than 1000 lines. Not bad for a hobby project.
Anyway. Better, later.
February 22nd, 2008
What’s the deal with alpha-sorted polygons those days? I hear more and more that engine X or Y doesn’t support them because “it’s too slow”. Errr, hello? We even sorted polygons on 8 Mhz Atari STs, I assume you can manage to do the same on a 3 Ghz multi-core machine? Sure the number of polygons has increased, but so has the CPU speed. So what’s the problem?
So, what’s your excuse already?
It had to happen: the STL rant
February 22nd, 2008
It’s not just that I don’t like the STL, it’s simply that I don’t need it.
If I need a basic container (linked list, vector…), the STL doesn’t help much because I can use my good old versions from 10 years ago.
If I need a more advanced container (e.g. a map), the STL doesn’t help much because custom versions are way faster anyway.
If I need a sort, I usually want a radix. Here again the STL doesn’t help.
If I want to disable exceptions for performance reasons, the STL doesn’t help.
If I want to save memory, the STL definitely doesn’t help.
If I want to debug my code easily, if I want to avoid “byzantine syntax” in my code, if I want to keep my compile times low or avoid insane code bloat, again, the STL fails.
So, really, why exactly should I bother? Just because it’s “standard” ? Are you insane? What does that buy me exactly? Isn’t that a lot of troubles for very dubious benefits?
STL horror stories on top of my head:
Please use and abuse the STL, it makes my life that much easier when it comes to beating the competition. Maybe exceptional products are not written with “standard” code, you know…
Faster convex-convex SAT : partial hulls
February 22nd, 2008
Here’s a question I received in my mailbox a while back:
I am looking into the SAT code for small convex meshes here at the moment and it doesn’t seem very effcient. Can you share some ideas how to reduce the number of tests. Especially the number of edge/edge tests seems to grow huge.
There would be a lot to say about this. But one way is to replace colliding convexes with simpler versions (I call them “partial hulls”). Take a look at the following picture:
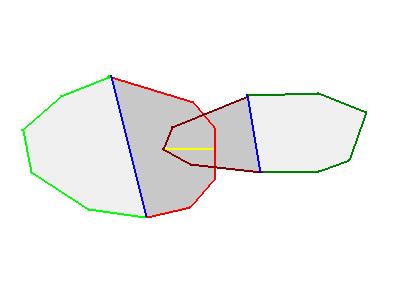
The two overlapping convexes have a red part and a green part. The key observation is that the penetration depth and the penetration direction (the yellow line) do not depend on the green parts - which can be safely ignored. The penetration would be the same if the convexes would be “closed” by the blue segments.
So the trick is simple in theory: ignore the green parts, and compute the penetration distance using the “partial hulls” enclosed between the red and blue segments. It has two direct benefits:
How to implement this efficiently is another (long) story, but here is a small proof-of-concept test that already runs orders of magnitude faster than the brute-force Separating Axis Theorem.
February 21st, 2008
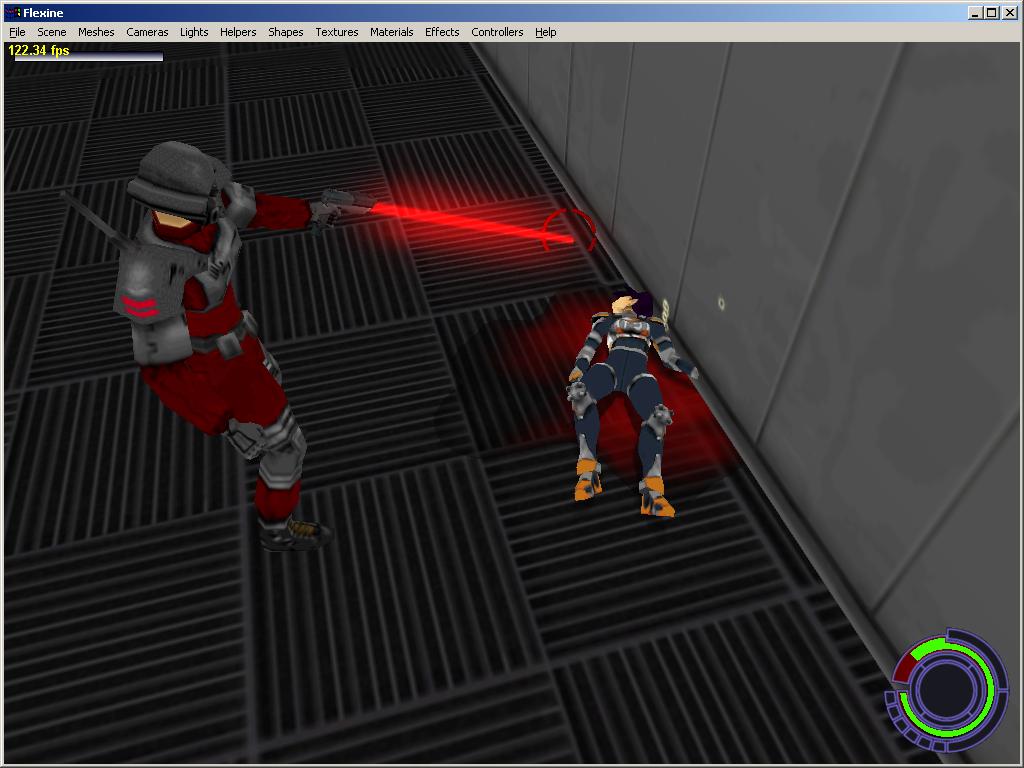
Added a “blood puddle” effect to Konoko Payne. It’s a lot of technology just for a small effect:
The effect is only played when you finish opponents with the pistol (Black Adder). It doesn’t appear when you finish them with hand-to-hand combat, that way the effect is not over-used.
In the end, it looks quite effective - especially in motion when the puddle grows and grows below the character.
February 21st, 2008
Don’t tell me it’s happening again. My website was down all day long. I just switched from one web hosting company to another, because the previous one had fucking lame miserable support and broken servers. I hope I didn’t go from Scylla to Charybdis here.
If you know a serious, rock-solid web hosting company, feel free to drop me a line about it.
February 20th, 2008
Heard at my previous job:
- “What is the black thing in the fridge, in the tupperware? Wasn’t that Anders’ salad?
- Anders?! But he left before I joined! The salad has been in the company longer than me!!”
…
February 19th, 2008
Most of us are manichaeist programmers: we see things in binary, either good or bad. This is the real root of all evil.
Joe loves tricky code. He enjoys assembly, over-abuses the float-as-int macro, doesn’t care at all about how “clean” or “unclean” the code is: he doesn’t even see it. He only sees the performance numbers on a benchmark. Joe thinks all compilers are evil by nature, and the last IDE he approved was Devpack 2.23.
Jack dreams in C++, loves the STL, enjoys template meta-programming, only uses Comeau compilers, and his code is already written with C++0x in mind. Compliance to the C++ standard is king, and runtime performance is a secondary concern better left to the one who knows best about this: the compiler.
Joe uses radix-sort.
Jack uses qsort.
Jack’s code crashes and exits as soon as a single texture is missing. He uses level 4 warnings-as-errors, his asserts can’t be ignored, and everything has to be perfect otherwise the game doesn’t even start. He uses exceptions and never tests pointers returned from an allocation: if it fails, an exception is thrown and the code handles it somewhere else.
Joe over-uses defensive programming, all pointers are tested in case malloc returns NULL, the game can start and run even when most assets are missing (missing textures are replaced with a procedurally generated “not found” texture, missing 3D models with a code-embedded rabbit object from GD Mag), his asserts have an “ignore always” button, exceptions and RTTI are disabled, and he uses a bunch of pragmas to disable all those useless compiler warnings.
Jack uses DX10 and his graphics code usually doesn’t run on cards from last year.
Joe still uses the Fixed Function Pipeline and misses the good old days of software rendering.
Jack uses proper O(n^3) LCP solvers, doubles for more accuracy, and uses distance queries for collision detection - penetration is forbidden.
Joe uses hacky linear-time solvers, floats, and he computes penetration depths with heuristic, borderline artistic, experimental code.
Jack wants all the string functions as members of the string class, because it’s “object oriented”. “There’s a string class, it should encapsulate all the string-related functions, otherwise it’s not clean.”
Joe doesn’t want a string class at all. He wants strcpy, strlen, and const char*.
So who’s right?
Well: Both and none. “Good” and “bad” doesn’t cut it here. It is not enough to stand on one side of the fence and blindly follow the rules or apply the recipes from your camp. The job is to be smart enough to know when to bend or break the rules. That’s the hard part: to give the recipe a subtle twist at the right moment. Anybody can program by the rules. Great programmers are the ones who know when to bypass them, how to bypass them, and who are not afraid of doing so.
In other words and as usual, the trick is to be flexible. The best thing to do is to be a mix of both Joe and Jack. And to handle your strings this way.